
As discussed in my previous post, where I mentioned that vSphere 6.5 was announced and I covered all the vSphere 6.5 new features and provided an overview of all of them.
In today's post, we will dig deep into one of the features - HA that has long been part of vSphere but has seen some major improvements in this release.
So let's just jump right in and check the vSphere 6.5 new features for High Availability (HA).
One of the first changes that you would notice is that in the cluster settings, the feature is no longer called HA but has been renamed to vSphere Availability.
The reason behind this is that there is a new feature that has been added in this section but is not implemented using HA.
There are five major things that I want to cover in this post which are:
- Admission Control
- Restart Priority enhancements
- HA Orchestrated Restart
- ProActive HA
- Quarantine mode
Admission Control Settings
There have been a lot of changes from the UI perspective from the previous version of the vSphere. Below is the screenshot of the new UI.
Now, let us take a look at them one by one and understand the changes.
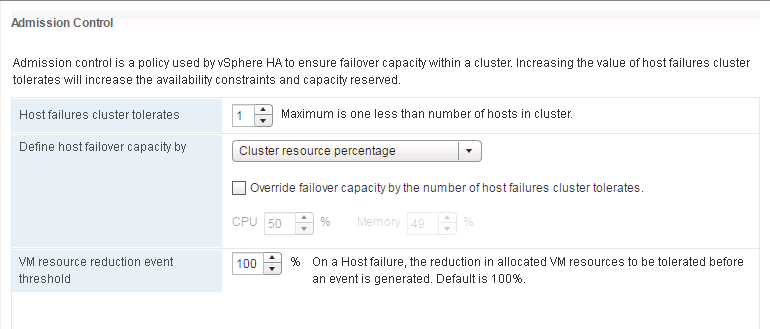
The new default setting for the HA Admission Control settings is "Cluster Resource percentage".
In the screenshot, we see that the "Host failures cluster tolerates" is equal to 1 and the "Define host failover capacity" is set to "Cluster Resource percentage".
What this means is that the cluster tolerate one host failure and it automatically calculates the Cluster resources that needs to be reserved for this.
You would notice that both the reserved CPU and Memory resources are set to 50% because I have two hosts that are part of this cluster.
Similarly, if I had three hosts, then the reserved resources will be 33% and for 4 hosts, it would be 25% and so on.
The main advantage of this setting is that you do not have to change the reserved cluster resources as it would calculate itself based on the host failures that the cluster can tolerate when a host is added or removed from the cluster.
And the old settings are also available as with the previous versions of the vSphere which are "Slot Policy" and "Dedicated failover hosts"
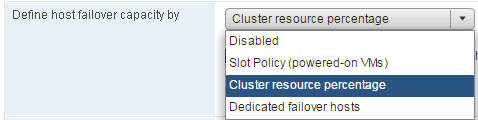
Let us say that you do not want to use this setting which calculates the reserved resources automatically, then is an override switch available.
You can check this box and set the reserved resources manually for both the CPU and Memory.
Another interesting policy in the Admission Control settings is the “VM resource reduction event threshold”.
Previously HA would restart the VMs on available hosts within the cluster if the host failure occurs, but they might suffer from performance degradation.
With this policy enabled, and the default value is 100% which you should ideally change to some other value based on business requirements, a warning message is generated if these thresholds are crossed.
Let us look into this with an example. If I have 4 hosts with 20 GB of Memory each, the total memory is 80 GB. And the setting has 1 host failure to tolerate. The VMs running in the cluster have active memory utilization of 70GB. The resource reduction tolerated is set to 0%.
If one of the hosts fails, we will only have 60 GB available memory resources. But the VMs need 70 GB to actively run, therefore a warning can be issued.
Restart Priority Enhancements
One of the vSphere 6.5 new features or enhancements in terms of HA is the addition of two more priorities, Highest and Lowest in addition to High, medium, low, which were already present in previous releases of vSphere.
To use this feature, select the cluster, click on Configure tab and select VM Overrides. You can now click on Add button to create the overrides for the important VMs.
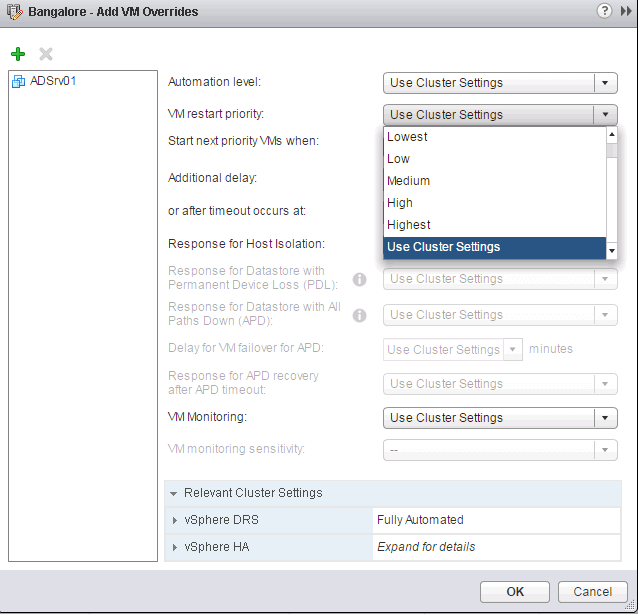
In the above image, I have one of the VMs to have the highest priority. If there is a host failure and if this VM along with the other ones has to restart, it will get the Highest priority than the other VMs.
You can further define when will the next priority group will be restarted based on the options below.
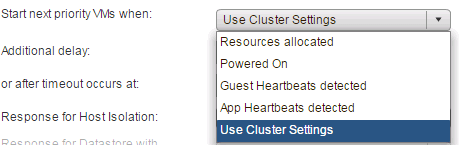
In most cases, I would recommend using the "Guest Heartbeat detected" which relies on VMware Tools as seen above.
Other options available are:
- Resources allocated.
- Powered ON.
- App Heartbeat detected.
In cases, where you do not have VMware Tools installed, there is a default timeout of 600 seconds which can be changed based on use cases.
HA Orchestrated Restart
This is one of the vSphere 6.5 new features that is part of HA and it is called HA Orchestrated Restart.
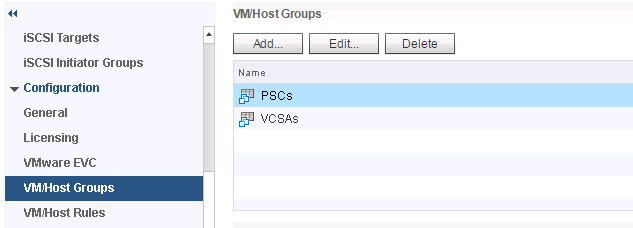
Let us look at this as an example. I have certain PSCs in my environment that I would like to start first and then start the vCSA machines.
Here I have created two groups called PSCs and vCSAs and added appropriate VMs to them.
Once done, we will now create a rule that will state that the PSCs need to restart first and only then the vCSAs as seen below.
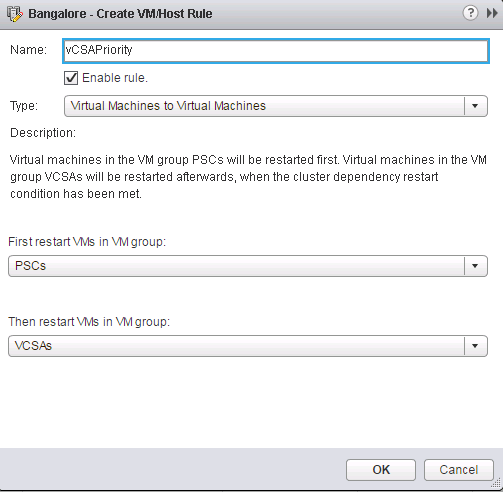
One thing to keep in my mind is that if the PSCs do not start, then the vCSAs also will not be restarted as these are "hard rules" and cannot be violated.
ProActive HA
ProActive HA is another new feature that is introduced with this release of vSphere. It actually depends on DRS to perform the migrations of the VM from one host to another.
This feature is solely introduced to reduce VM downtime. It also completely depends on the Hardware vendors wherein they will be creating a Monitoring tool that can be integrated with vSphere in the form of plug-ins.
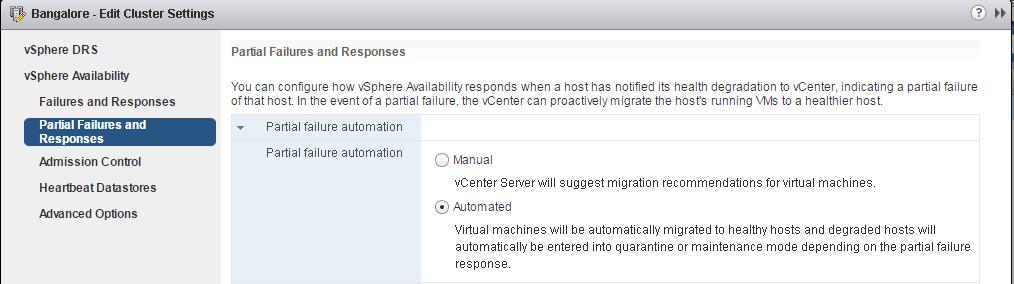
Let us look at the use case of this feature. For example, the Memory DIMM on the ESXi host is failed which means that the host is in a "degraded" state and it is possible that it can lead to a possible host down situation, during which the VMs will be restarted on the other healthy hosts within the cluster.
With the help of Health Providers, we can capture the memory DIMM degradation event and the vCenter will then mark this host as degraded and the VMs will be migrated to healthy hosts.
The states are “Healthy”, “Moderate Degradation”, “Severe Degradation” and “Unknown”.
ProActive HA can respond to different types of failures. Currently, there are five failure events that it can understand.
- Power Supply.
- Memory.
- Fan failure.
- Storage.
- Network.
Quarantine Mode
In the event of a host degradation, the vCenter can possibly migrate the VMs and put the hosts in one of the two modes: Maintenance mode and Quarantine mode.
In short, Quarantine mode state allows you to configure vMotion of VMs of the cluster if there will be:
- No performance impact on any VM in the cluster (Resource availability)
- None of the hard rules are compromised.
Quarantine mode also makes sure that none of the new VMs in the cluster are placed on that host.

Therefore, there three options available for Partial failures:
- Quarantine mode – Do not add new VMs to the host.
- Maintenance mode – Migrate all VMs of the host and place it in maintenance mode
- Mixed mode – moderate failure, keep VMs running. But for severe failures, it will migrate VMs.
That is all I have for today, I hope you found this informative and thank you for reading!


