
In this post of the Kubernetes 101 Series, we will discuss the Kubernetes Cluster Architecture which will cover the core concepts and also the Kubernetes components that make up a cluster. Feel free to check my previous post, where I discussed what is Kubernetes and why should you care?
So let's cover the core concepts like Kubernetes Cluster Architecture. First and foremost, we should define what a node is. A node is essentially a physical or virtual machine where Kubernetes is installed along with the container runtime like docker, CRI-O, containerd, etc.
There are two roles that a node can be in. They are called master and worker roles. A node that runs the master role is called a master node and a node that runs a worker role is called a worker node.
There should be at least 1 or more master node in a Kubernetes cluster and there can be 0 or more worker nodes.
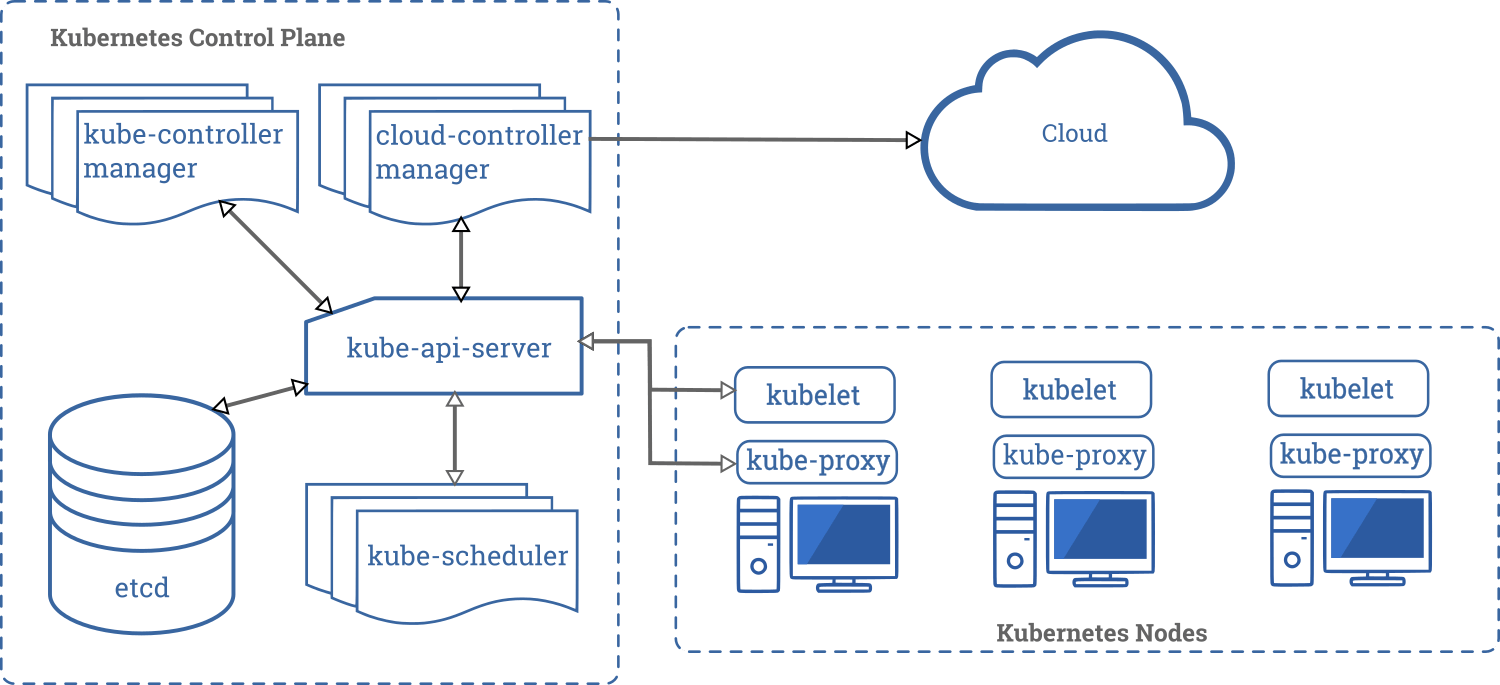
Image Credit - Kubernetes
From the above image, we can clearly understand that the Kubernetes cluster essentially consists of two things:
- Control Plane which consists of one or more master nodes.
- Compute Machines or worker nodes.
The Control Plane consists of the master node/s and each of the nodes have the below components:
- kube-apiserver: The Kubernetes API Server is the front end of the Kubernetes control plane. This is how you would interact with the Kubernetes cluster.
- kube-scheduler: The scheduler is responsible for distributing/scheduling the pods on the worker nodes based on the resource requirements of the pods. A pod is the smallest object that you can create on a Kubernetes cluster which can run one or more containers.
- kube-controller-manager: The controller is the brain behind the entire Kubernetes Orchestration. It is responsible to make sure that all objects are running in a healthy state within the Kubernetes Cluster. For example, if a pod goes down, it is the responsibility of the controller to schedule the pod on the same or a different worker node.
- etcd: It is a distributed reliable key-value store database to store data used to manage the Kubernetes cluster. It is the ultimate source of truth about the cluster.
The following components run on each of the worker nodes in your Kubernetes cluster:
- Container runtime engine: To run the containers on the worker nodes, you need a container runtime engine. Docker is just one example that we will be using throughout this series, but Kubernetes also supports other Open Container Initiative-compliant runtimes such as rkt and CRI-O.
- kubelet: It is a tiny application that runs on each of the worker nodes on the cluster. It is responsible to make sure that the pods are running as expected in the cluster.
- kube-proxy: It is a network proxy that runs on each worker node in your cluster, implementing part of the Kubernetes Service concept. It maintains network rules on nodes. These rules allow network communications inside or outside of your Kubernetes cluster.
Well, that is all we need to know about the Kubernetes cluster architecture and this concludes the post. In the next post, we will look at how to install a minikube of your machine so that you can practice what we go through in this series.
I hope this was informative and thank you for reading!


